Embeddings: The Foundation of Semantic Search
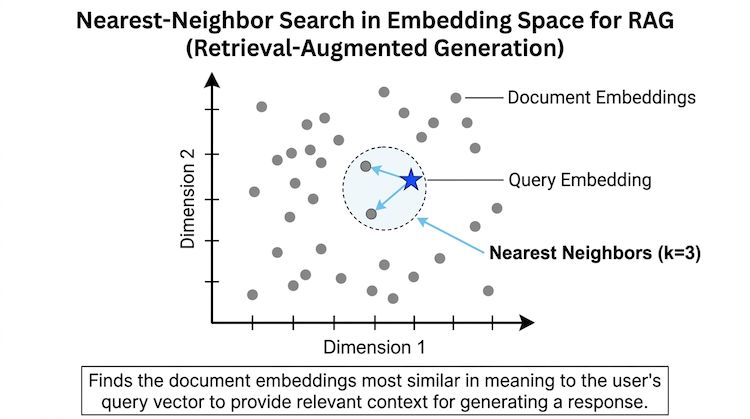
Embeddings are dense vector representations of text (or other content). They capture meaning so that similar texts end up with similar vectors. That's the foundation of semantic search: you embed the query and the documents, then find documents whose vectors are closest to the query vector.
What is an embedding?
An embedding model takes text and outputs a fixed-size list of numbers—often 256, 768, or 1536 dimensions. The model is trained so that semantically similar texts are close in this space. 'Reset password' and 'forgot my password' will have similar embeddings even though the words differ.
Code example
from openai import OpenAI
client = OpenAI()
texts = [
"How do I reset my password?",
"I forgot my login credentials"
]
response = client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
# response.data[0].embedding and response.data[1].embedding
# will be close in distance (e.g. cosine similarity)Popular embedding models include OpenAI's text-embedding-3, Cohere's embed, and open-source options like sentence-transformers. Choose based on language support, dimension size, and cost.
Distance and similarity
Vector databases usually rank by similarity (e.g. cosine similarity or dot product) or distance (e.g. L2). Smaller distance or higher similarity means more relevant. For retrieval you typically take the top-k most similar vectors. The same embedding model must be used for indexing and querying, or the space won't be comparable.