RAG for Customer Support
RAG is well-suited for customer support: agents or chatbots can answer from knowledge bases, product docs, and policies without memorizing everything. The system retrieves the relevant passage and the model generates a clear, grounded answer—often with a link to the source so the customer can read more.
Architecture
Support content is chunked, embedded, and stored in a vector index. When a customer asks a question, the query is embedded and the top-k chunks are retrieved. The LLM gets those chunks plus the question and produces an answer. Citations can be shown in the UI so agents and customers can verify.
# Support flow
query = customer_message # e.g. "What's your return window?"
chunks = vector_db.search(embed(query), top_k=5)
answer = llm.generate(
system="You are a support assistant. Answer only from the context. Cite sources.",
context=chunks,
question=query
)
# Return answer + chunk URLs for citations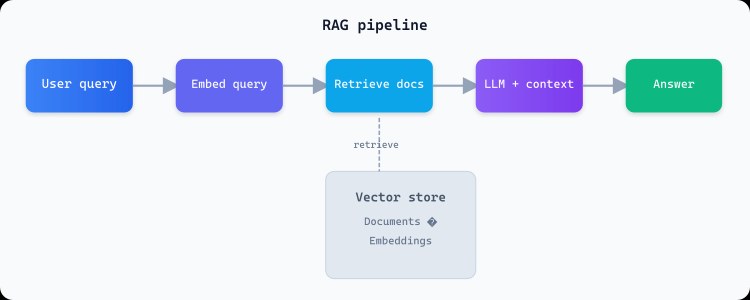
Benefits
Faster resolution, consistent answers, and less dependency on tribal knowledge. Updating the knowledge base updates answers without retraining. Combined with human-in-the-loop for edge cases, RAG makes support scale.
What to include in the knowledge base
Product docs, return and refund policies, FAQs, troubleshooting guides, and internal playbooks. Keep content current and remove or archive outdated material so the model doesn't cite wrong information. Structure and chunk size affect whether the right passage is retrieved for each question.