Vector Databases Explained
Vector databases store and retrieve data by similarity rather than exact match. They index high-dimensional vectors (embeddings) and support fast nearest-neighbor search, which is essential for RAG and semantic document search. Unlike traditional databases that match keywords, vector databases find items that are conceptually close in a mathematical space.
How vector search works
When you embed a document or a query, you get a vector—a list of numbers. Similar content produces similar vectors. Vector databases use algorithms like HNSW (Hierarchical Navigable Small World) or IVF (Inverted File Index) to find the most similar vectors quickly, often in milliseconds, even across millions of documents.
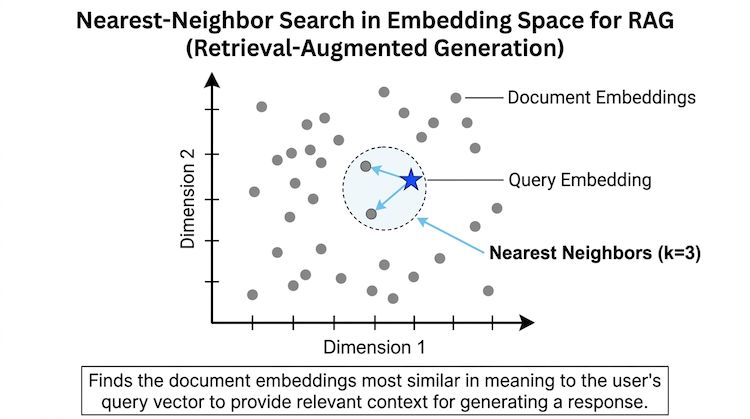
Example: embedding and search
from openai import OpenAI
client = OpenAI()
# Embed a query
response = client.embeddings.create(
model="text-embedding-3-small",
input="How do I reset my password?"
)
query_vector = response.data[0].embedding
# Search (pseudocode - your vector DB API will differ)
results = vector_db.query(
vector=query_vector,
top_k=5,
include_metadata=True
)Choosing a vector database
Popular options include Pinecone, Weaviate, Chroma, Qdrant, and pgvector (PostgreSQL extension). Consider scale (documents and QPS), latency requirements, filtering (metadata + vector), and whether you need a managed service or self-hosted. Many teams start with a simple option like Chroma or pgvector and move to a managed service as scale grows.
# Comparison (simplified)
# Managed: Pinecone, Weaviate Cloud, Qdrant Cloud
# Self-host: Chroma, Qdrant, Weaviate, pgvector
# Scale: Millions of vectors, sub-100ms latency
# Filtering: Often need metadata (e.g. department, date) with vector search