What is ERAG?
Most people describe RAG as: turn the question into an embedding, pull the nearest document chunks, paste them into a prompt, and let the language model answer. That pattern works well for narrative questions, such as policies explained in prose, how-to guides, and FAQs written like paragraphs. It starts to break when the truth lives in tables, in conflicting versions of the same rule, in effective dates, or in numbers that must stay exact.
What ERAG means here
ERAG stands for Extended RAG: you keep retrieval and generation at the center, but you add layers that treat evidence as something you can type-check, route, and validate, not only as similar-looking text. In this article the term describes an architecture shape, not a separate retail product line. Platforms such as FAQ Ally still rely on hybrid retrieval over your trained documents; the "extended" part is what wraps that core so answers stay aligned with what your data can actually support.
Where plain RAG often strains
Spreadsheets, invoices, subscriptions, and usage rows carry precise figures. A model that only sees fuzzy chunks can round, blend, or invent numbers that sound plausible. When two documents disagree, vector rank alone does not tell the system which authority wins. Year-to-date or full-period questions may only retrieve part of the timeline, yet fluent language can mask the gap. Policies that change on a calendar date need logic, not just the chunk that ranked highest. Diagrams and screenshots may hold the fact while the surrounding text stays vague. Extended RAG is aimed at these situations by combining narrative context with structured signals and explicit checks.
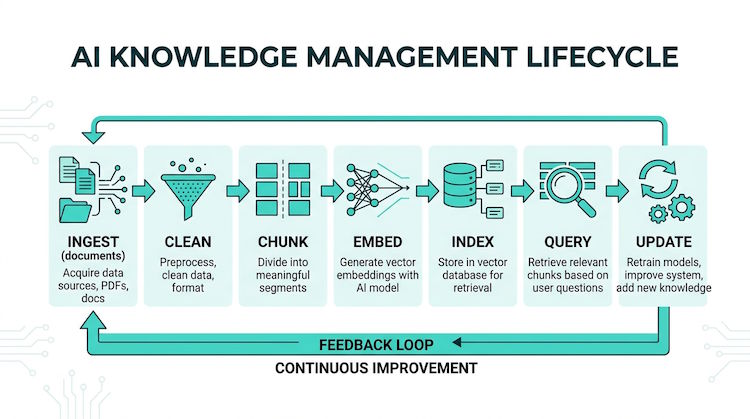
What an extended stack typically adds
Smarter retrieval
Hybrid search blends dense vectors with keyword-style signals so exact tokens (SKUs, codes, titles) can reinforce or correct pure semantic matches. Metadata (document type, headings, entities) helps filter and expand the chunk pool. Reranking can sharpen the short list before anything reaches the model. For long or aggregate-style questions, adjusting pool size and similarity floors keeps the assembled context shaped to the question instead of a generic grab bag.
Structured evidence
When training and extraction fit your content, key facts can land in typed records: line items, financial summaries, contract fields, or versioned policy objects. That gives planners something to sum, compare, or reject against. That work is awkward when every clue is buried in prose chunks alone.
Planning and routing
Lightweight understanding of the query can steer each turn toward the right branch: classic chunk-and-generate for story-like answers, record-backed computation when rows support a totals question, or structured-only output when the database has an answer even though vector search returned nothing useful. Deterministic steps can resolve version conflicts or money-row disagreements before the final answer is phrased.
Validation and guardrails
Checks can run before and after the main completion: block unsafe inputs, re-verify weak retrieval when citations are strict, align displayed numbers with planner output, or run a bounded post-answer review against retrieved text. Refusal and shortening paths matter when evidence is thin, which is preferable to confident guessing.
How this shows up at question time
For many turns the experience still looks like familiar RAG: normalize the query, search, assemble numbered context, generate. When structured data fits the intent, the system may lean on typed rows for arithmetic and coverage, then fold those results back next to retrieved passages. Caches or records-first shortcuts can skip hybrid search on some paths; that does not erase the overall design; it reflects that real deployments branch.
Surfacing uncertainty
Strong pipelines admit when data is incomplete: partial periods with explicit warnings, visible explanations when rows conflict, or preambles that state ambiguity before the body of the answer. Those behaviors reduce silent failure. They do not remove the need for human review on high-stakes compliance work.
Limits to keep in mind
Extended patterns do not replace clean sources, thoughtful training hygiene, or re-embedding when you change models. Typed extraction only helps where your documents match what extractors expect. Multimodal image search depends on compatible files and product capabilities. Automated checks complement judgment; they do not substitute for it where liability is real.
Summary
RAG is still retrieve, then generate. ERAG (Extended RAG) keeps that core and hardens it with structured evidence, routing, and validation so answers track numbers, conflicts, coverage, and policy versions, not only the top similar paragraphs.
For a deeper walkthrough of how FAQ Ally approaches Extended RAG, including hybrid retrieval, structured records, and post-answer checks, see the FAQ Ally team write-up linked below.