What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a technique that combines large language models (LLMs) with external knowledge retrieval. Instead of relying solely on the model's training data, RAG systems fetch relevant documents at query time and use them to ground the model's responses. That means answers can be accurate, up-to-date, and traceable to your own sources.
How RAG works
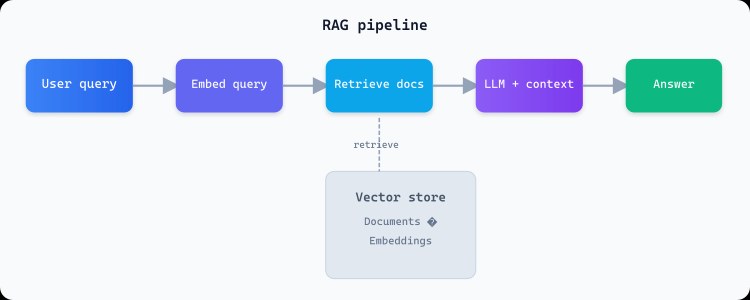
When a user asks a question, the system first converts the query into a vector (embedding) and searches a knowledge base for the most relevant chunks. Those chunks are then passed to the LLM as context, along with the original question. The model generates an answer that is grounded in the retrieved information rather than invented from training data.
Key benefits
RAG keeps the base model unchanged while letting you add or update knowledge by changing the documents in your index. You get traceable answers with source citations, which is critical for compliance and trust. Because retrieval happens at query time, the system can reflect the latest policy or product information without a single model retrain.
When to use RAG
RAG is ideal when your knowledge changes often, when you need citations, or when you have proprietary or internal documents. It avoids retraining the model and keeps a clear audit trail. Tools like FAQ Ally implement RAG so teams can answer questions directly from their documentation.
# Simplified RAG flow (pseudocode)
query = "What is our vacation policy?"
query_embedding = embed(query)
relevant_chunks = vector_db.search(query_embedding, top_k=5)
context = "\n\n".join(chunks)
prompt = f"Based on: {context}\n\nQuestion: {query}"
answer = llm.generate(prompt)Limitations to keep in mind
RAG depends on retrieval quality: if the right chunks are not fetched, the answer may be wrong or incomplete. Chunk size and overlap, embedding quality, and the choice of top-k all matter. For very long documents, you may need hierarchical or multi-step retrieval. Even with good retrieval, the model can still make mistakes, so citations and human review remain important.