Why AI Hallucinates
AI hallucinations occur when large language models generate plausible-sounding but incorrect or fabricated information. They happen because LLMs predict the next token from patterns in their training data—they have no built-in mechanism to distinguish fact from fiction. Understanding why this happens is the first step to building more reliable systems.

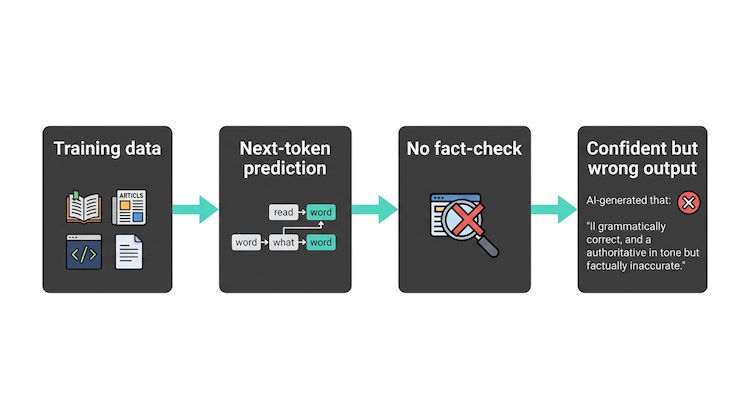
Root causes
Models are trained to maximize the likelihood of the next token. They weren't trained to be fact-checkers. When the right answer is uncertain or the training data is biased or wrong, the model may still produce a confident reply. Gaps in knowledge, ambiguous questions, or out-of-domain topics increase the risk.
Mitigation strategies
Techniques like RAG ground the model in retrieved documents. You can also use system instructions that tell the model to say 'I don't know' when unsure, and to cite sources. Evaluation and adversarial testing help catch failures before they reach users.
# Adversarial test: question the doc can't answer
query = "What is our policy on time travel?"
# Good system: refuses or says "not in the documents"
# Bad system: invents a plausible-sounding policyTypes of hallucinations
Fabrication (inventing facts), outdated or wrong information (from training cut-off), attribution errors (citing the wrong source), and overconfidence (answering when it should refuse). Each suggests different mitigations: RAG for facts, refusal instructions for out-of-scope questions, and evaluation to catch attribution and overconfidence.